Nous avons vu hier, dans la première partie de cet article, en quoi consistait Internet. Nous savons donc qu'il s'agit d'un gigantesque réseau composé d'innombrables terminaux pouvant communiquer. Nous avons eu un aperçu des infrastructures, mais sommes restés très en surface concernant les applications déployées. Nous allons donc aujourd'hui nous intéresser plus en détails à quelques-unes des plus importantes applications d'Internet.
Mon intention n'est pas d'écrire un article sur les protocoles en vigueur, mais vous vous êtes rapidement rendus compte que ceux-ci ont toute leur importance lorsque l'on décortique Internet. Il est en effet difficile de parler de communication sans mentionner la façon dont celle-ci est définie. Ne vous étonnez donc pas d'en retrouver régulièrement dans les lignes qui suivent. Bien entendu, le but n'est pas forcément de tous les retenir, mais plutôt de comprendre les différents rôles qu'ils peuvent jouer.
Une architecture multi-couches
Avant de nous intéresser aux applications en tant que telles, penchons-nous tout d'abord sur la séparation en couches d'Internet. En effet, Internet apparaît comme un système extrêmement complexe, composé de multiples éléments. Afin de le structurer, il est courant d'organiser Internet selon un modèle en couches (5 comme défini plus bas, ou 7 selon le modèle OSI), appliqué à chaque noeud. Une telle architecture permet de simplifier le système et d'en analyser une partie spécifique et bien définie. Cette modularité permet par exemple de modifier l'implémentation de certaines fonctions d'une couche sans avoir à se soucier des autres: du moment que celle-ci garde la même fonctionnalité, qu'importe la façon dont elle est effectuée d'un point de vue extérieur.
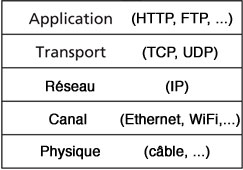
L'architecture en couches d'Internet, avec certains de leurs protocoles.
Source: Computer Networking (Kurose & Ross)
De cette manière, chaque protocole appartient à une unique couche. Les protocoles de la couche Application (HTTP, FTP ou SMTP par exemple) sont quasiment toujours implantés au niveau software sur les hôtes, puisqu'ils permettent la mise en oeuvre d'applications. Il en va de même pour ceux de la couche Transport (TCP ou UDP par exemple), qui gèrent les communications de bout en bout entre processus. Au contraire, les protocoles des couches Physique et Canal, responsables des communications au travers d'un canal spécifique, sont de par leur fonction typiquement implantés sur une carte réseau (cartes Ethernet ou WiFi par exemple). Enfin, la couche Réseau (protocole IP), qui assure l'acheminement des paquets d'information, est un mélange des deux. Un routeur ne contiendra donc que les trois dernières couches, les deux premières lui étant inutiles.
Cette rapide introduction à l'architecture en couches d'Internet nous permettra de mieux saisir les différents rôles de chaque intervenant dans la suite de notre lecture. Puisque nous allons parler d'applications, vous ne serez pas étonnés de constater que la plupart des protocoles cités se situent dans la couche Application.
La messagerie électronique
L'application de messagerie électronique (e-mail en anglais) est là depuis les balbutiements d'Internet et fut l'une des applications les plus populaires de ses débuts. Celle-ci est composée d'un logiciel permettant de gérer son courrier, appelé client de messagerie, de serveurs de messagerie ainsi que de différents protocoles afin d'assurer l'échange des messages d'un émetteur vers un ou plusieurs destinataires.
Chaque contact est identifié grâce à une adresse électronique, constituée de trois éléments. La partie locale identifie le nom d'utilisateur, généralement un nom de personne ou un nom de service. Vient ensuite le signe @, dont l'utilisation fut initiée par Ray Tomlinson en 1972. Il permet de séparer la partie locale du nom de domaine, identifiant le serveur de messagerie hébergeant la boîte électronique. Celui-ci sera traduit en adresse IP par le DNS, expliqué dans la première partie de cet article.
J'imagine que tout le monde s'en sert régulièrement et je ne vais pas vous apprendre comment faire pour envoyer un courriel à votre meilleur ami(e) habitant à l'autre bout du globe. Mais savez-vous ce qu'il se passe dès le moment où vous cliquez sur Envoyer?
Nous avons donc vu que le système de courriel repose sur trois composantes majeurs que nous allons approfondir ici dans le contexte où Juliette envoie un message à son correspondant Basile (prénoms choisis totalement au hasard).
Un client de messagerie permet à l'utilisateur de lire, composer, répondre, réexpédier et enregistrer ses messages. Citons par exemple Mail d'Apple, Mozilla Thunderbird ou une simple page Web dans un navigateur comme pour Hotmail. Et comme souvent, rien ne vous empêche de le faire en lignes de commande en utilisant le Terminal (en voilà une bonne résolution pour 2008 n'est-ce pas François?). Bon je vous l'accorde, ce n'est sans doute pas le moyen le plus convivial de traiter ses courriels!
Lorsque Juliette a fini d'écrire son message, son client l'envoie à son serveur de messagerie électronique (cuk.ch par exemple, si l'adresse est juliette@cuk.ch) où il sera placé en file d'attente afin d'être envoyé vers le serveur de messagerie électronique contenant la boîte aux lettres de Basile. Quand ce dernier voudra accéder à sa boîte depuis son client, le serveur de messagerie électronique l'authentifiera (notez que généralement il n'y a pas d'authentification lors de l'envoi, ce qui permet d'envoyer un courriel sous n'importe quel nom, même si l'adresse IP de la machine émettrice est conservée dans le contenu du courriel) puis délivrera le message reçu.
Au coeur de tout ce mécanisme, un protocole: SMTP (Simple Mail Transfer Protocol). Pas tout à fait en fait, puisqu'il n'est pas le seul, mais il s'agit là de l'élément principal. SMTP est utilisé pour transférer un courriel d'un client à un serveur de messagerie ainsi que d'un serveur de messagerie à un autre. Il utilise lui-même le protocole TCP (sur le port 25 pour être précis). Nous voyons donc ici que l'application de messagerie électronique utilise (entre autres) SMTP dans la couche Application puis TCP pour la couche Transport. De même que de nombreux protocoles, SMTP possède deux côtés: le côté client permettant d'envoyer un message vers un autre serveur, et le côté serveur, réceptionnant les messages entrant.
L'image du dessous montre le chemin complet parcouru par un message. Chaque étape est détaillé ci-après.
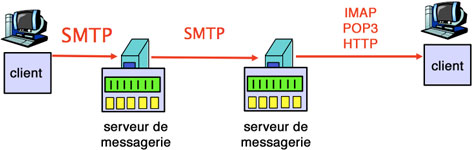
Le chemin parcouru par un courriel d'un client à un autre, avec les protocoles utilisés.
Source: Computer Networking (Kurose & Ross)
Lorsque Juliette envoie son courriel, son client de messagerie utilise SMTP afin d'envoyer le message sur son serveur de messagerie électronique, qui utilisera lui aussi SMTP (en tant que client) pour relayer le courriel directement vers le serveur de messagerie de Basile. Si par hasard le serveur de messagerie de ce dernier est inopérant, celui de Juliette tentera d'envoyer le message vers celui-ci à intervalles réguliers (toutes les heures par exemple) jusqu'à ce que le transfert soit effectué.
Maintenant que le message se trouve dans la boîte aux lettres de Basile, sur son serveur de messagerie électronique, il va de son côté vouloir le lire, depuis son propre client de messagerie. Celui-ci devra donc rapatrier le message sur l'ordinateur de Basile. Pour cela, il existe trois manières de faire, à savoir trois protocoles différents dont les noms ne vous sont sans doute pas inconnus. Si SMTP s'occupe de l'envoi d'un courriel, c'est grâce aux protocoles POP3, IMAP ou HTTP que le client pourra le récupérer.
POP3 (Post Office Protocol) est le plus ancien et aussi le plus simple, d'où ses fonctionnalités plutôt limitées. Lorsque Basile choisit de relever son courrier, son client établit une connexion TCP vers son serveur de messagerie électronique (sur le port 110). POP3 se charge ensuite d'authentifier l'utilisateur grâce à son nom et son mot de passe, puis s'occupe de la transaction, permettant au client de récupérer les courriels. Durant cette phase, le client a la possibilité de marquer chaque message pour qu'il soit effacé (ou non) plus tard. Finalement, lorsque la connexion est close, le serveur de messagerie efface les messages marqués.
Cette façon de faire, à savoir télécharger les messages du serveur vers sa machine puis (éventuellement) les effacer, peut poser un problème: comment faire lorsque l'on veut consulter son courrier depuis des ordinateurs différents? En effet, un message récupéré par un client sur une machine ne sera plus disponible sur le serveur, et ne pourra donc plus être consulté ailleurs.
S'il existe aujourd'hui des options permettant de conserveur un message sur le serveur, ce problème fut une des raisons qui donna le jour au protocole IMAP (Internet Message Access Protocol), plus complexe mais plus abouti. En effet, ce protocole permet de conserver la hiérarchie complète d'une boîte à lettres (à savoir messages et d'éventuels dossiers de rangement) quelle que soit la machine sur laquelle on se trouve. L'utilisateur a donc la possibilité de créer un dossier spécial, d'y déplacer certains messages, d'effectuer des recherches, et se retrouvera avec exactement le même contenu, quel que soit l'ordinateur qu'il utilise.
Enfin, plus en plus d'utilisateurs accèdent également à leur boîte aux lettres au travers de leur navigateur Web, comme il est possible de le faire avec Hotmail, Yahoo ou Google. De cette façon, le client de messagerie est donc un simple navigateur communiquant avec le serveur de messagerie via le protocole HTTP (HyperText Transfer Protocol). Nous reparlerons de ce protocole en abordant ce qu'est le Web.
Un rapide mot encore sur le contenu d'un courriel. Un message, vous vous en doutez peut-être, ne possède pas simplement le texte que vous avez composé. Il contient en effet plusieurs en-têtes (émetteur, destinataire, sujet, ...) et il possible d'y joindre des fichiers (grâce à MIME). Si à l'origine l'encodage du texte était du simple ASCII, d'autres encodages sont aujourd'hui supporté (UTF-8, etc...), offrant un plus vaste choix de caractères, et il désormais possible de mettre en forme un message grâce au HTML.
Le World Wide Web
Le World Wide Web (la toile d'araignée mondiale en français) fut inventé au CERN par Tim Berners-Lee entre 1989 et 1991. Le Web est une application d'Internet client-serveur permettant à un utilisateur d'envoyer une requête à un serveur web au travers d'un navigateur (Safari ou Firefox, par exemple). Le navigateur est donc un composant de cette application, au même titre qu'un standard pour le format des documents, le HTML (HypterText Markup Language dont il a déjà été question dans cet article), les serveurs web (Apache) et le protocole HTTP (HyperText Transfer Protocol) que nous avons entrevu plus haut, définissant la façon dont les messages sont échangés entre le navigateur et le serveur web.
Ainsi, de façon très générale, lorsque vous entrez dans votre navigateur une adresse telle que https://www.cuk.ch/articles/3533, celui-ci enverra une requête HTTP vers le serveur hébergeant le domaine cuk.ch et contenant donc toutes les ressources nécessaires au site. Le serveur web traitera alors cette requête puis renverra une réponse HTTP (une page HTML ici) au navigateur, qui se chargera alors de l'afficher correctement. Un navigateur joue donc le rôle de client HTTP et de moteur de rendu des standards du Web.
Regardons maintenant plus en détail ce qu'il se passe sous le capot. https://www.cuk.ch/articles/3533 est ce que l'on appelle une URL (Uniform Resource Locator), une chaîne de caractères combinant les informations nécessaires pour indiquer à un logiciel comment accéder à une ressource d'Internet.
Une URL contient plusieurs informations, notamment le protocole de communication, un nom d'utilisateur, un mot de passe, une adresse IP ou un nom de domaine, un numéro de port TCP/IP, un chemin d'accès ou une requête.
Voici comment l'adresse https://www.cuk.ch:80/articles/3533 est décomposée:
- http est le nom du protocole utilisé, ici HTTP (un autre exemple serait ftp). Les deux points servent uniquement de séparation alors que // est une chaîne de caractères utilisée pour les protocoles dont la requête comprend un chemin d'accès, permettant de préciser et localiser le service avant ce chemin.
- www.cuk.ch est le nom de domaine du serveur hébergeant la ressource demandée. Il est possible d'y entrer directement l'adresse IP de celui-ci. Comme nous l'avons vu dans la première partie de cet article, s'il est habituel d'écrire un nom de domaine, la machine ne comprend que l'adresse IP. Le nom de domaine sera donc converti par le DNS en une adresse IP.
- :80, mais qu'est-ce que cela vient faire dans cette adresse? Il s'agit en fait du numéro de port TCP/IP utilisé pour établir la connexion. Celui-ci doit être précisé uniquement s'il diffère du port standard, à savoir le port 80 pour HTTP. Pour cette raison, le port 80 n'apparaît jamais dans les URL, mais rien ne vous empêche de l'indiquer, vous verrez que le résultat sera le même. Il en existe bien sûr beaucoup d'autres (21 pour FTP par exemple).
- /articles/3533 est le chemin d'accès de la ressource demandée; il indique son emplacement exact sur le serveur.
Lorsque vous tapez sur Enter dans votre navigateur, celui-ci, en tant que client HTTP, initie une connection TCP vers le serveur www.cuk.ch sur le port 80. Le client HTTP envoie alors une requête HTTP au serveur, incluant le chemin de la ressource désirée (/articles/3533). Le serveur reçoit le message, récupère les données correspondantes au chemin stockées sur son disque, les encapsule dans un nouveau message HTTP et renvoie la réponse au client. Une fois les données reçues, la connexion TCP est close et le navigateur extrait le contenu de la réponse afin de générer l'affichage. Le message peut contenir du simple texte, mais également des images ou des vidéos par exemple.
Le transfert de fichiers: FTP
Le transfert de fichiers fut une des premières applications d'Internet, permettant notamment aux scientifiques de partager facilement leurs recherches. Grâce au protocole FTP (File Transfer Protocol), l'utilisateur peut rester bien tranquillement assis devant son ordinateur et envoyer ou récupérer des fichiers sur une machine distante.
FTP est également basé sur le modèle client-serveur. Le serveur est un ordinateur sur lequel fonctionne un logiciel appelé serveur FTP, rendant accessible son contenu depuis l'extérieur. Pour y accéder, il faut utiliser un logiciel client FTP, comme par exemple Transmit ou Cyberduck, ou encore en ligne de commande.
Via son client, l'utilisateur entre d'abord le nom de domaine (ou l'adresse du serveur) auquel il veut se connecter. Le client FTP ouvre alors une connexion TCP sur le port 21. L'utilisateur s'authentifie avec un nom et un mot de passe puis, s'il y est autorisé, peut alors échanger des fichiers entre sa propre machine et l'ordinateur connecté. L'échange de données se fait sur une autre connexion TCP, sur le port 20. FTP utilise donc deux connexions TCP en parallèle: une connexion de contrôle, pour l'identification, les mots de passe ou les commandes FTP, et une connexion de données où celles-ci sont échangées.
Le peer-to-peer
Contrairement au Web et aux transferts de fichiers FTP basés sur la relation client-serveur, le peer-to-peer (pair-à-pair en français, généralement abrégé P2P) permet d'éviter d'avoir à stocker des informations sur un (ou plusieurs) serveurs puisque chaque client (ou noeud) est un serveur potentiel, au même titre qu'il est client. Autrement dit, lorsque vous téléchargez un fichier BitTorrent ou dialoguez sur Skype, non seulement vous êtes client en recevant des données, mais vous faites également office de serveur puisque votre machine envoie de l'information à d'autres utilisateurs. Il s'agit donc d'une décentralisation des systèmes permettant la mise à disposition de ressources au sein d'un réseau et de partager simplement des fichiers, des flux multimédia continus ou de la téléphonie sur Internet.
Grâce à l'utilisation d'un logiciel prévu à cet effet, n'importe quel utilisateur peut se connecter sur un de ces réseaux pour y obtenir ou proposer des ressources. Si des logiciels comme Skype ou Zattoo profitent de cette technologie pour la téléphonie ou la télévision, la plupart des réseaux (Gnutella, FastTrack, ...) permettent le partage de fichiers (bien souvent dans un contexte illégal d'ailleurs).
Une première approche afin de localiser un fichier est d'utiliser un index centralisé. Tel était le cas de Napster, le premier système de partage de fichiers à large échelle utilisant le P2P. Avec ce système, un regroupement de serveurs (un méta-serveur) gère un service d'indexation dynamique des fichiers partagés. Lorsqu'un client propose un fichier, l'application informe le serveur d'index qu'un nouveau fichier est rendu disponible par telle machine, en conservant son adresse IP. Quand un utilisateur recherche un objet, une requête contenant le titre de l'objet est envoyée au serveur qui renverra alors la liste des noeuds possédant ce fichier.
Cette architecture hybride client-serveur/P2P pose plusieurs problèmes. En effet, il suffit que le serveur d'index plante pour que toute l'application ne réponde plus. De plus, lorsque le nombre d'utilisateurs est trop élevé, le système peut devenir inutilisable, la charge sur le serveur d'index devenant trop grande. Finalement, et il s'agit là plutôt d'une question de droits que de technique, lorsqu'une entité possède un serveur d'index centralisé, il est possible de l'attaquer juridiquement si le contenu n'a pas a être partagé, ce qui peut se traduire par la fermeture du serveur. C'est exactement ce qui s'est passé avec Napster qui proposait des fichiers musicaux.
A l'opposé se trouve une architecture totalement décentralisée, où l'index est distribué parmi les pairs, utilisée notamment dans la première version du protocole Gnutella. Chaque noeud recense les fichiers qu'il met lui-même à disposition. Les pairs sont regroupés en réseaux abstraits (dans le sens où il n'ont pas de lien physique directe) où chaque noeud est connecté à un petit nombre d'autres noeuds (ses voisins). Lorsqu'un utilisateur recherche un fichier, son client questionne ses voisins, qui passeront le mot à leurs propres voisins et ainsi de suite. Lorsqu'un noeud possède le fichier, un message de réponse remonte la connexion jusqu'au client et l'échange peut alors s'effectuer, le client ayant trouvé un serveur.
Une troisième approche, combinant le meilleur des deux architectures vues plus haut, est basée sur des interconnexions de "super pairs" (super peers). A l'instar d'un système totalement décentralisé, cette approche n'utilise pas de serveur dédié pour l'indexation de fichiers. Cependant, tous les pairs ne sont pas égaux. En effet, il existe une hiérarchie de pairs, où les noeuds ayant la plus grande bande passante sont désignés super pairs. Un pair ordinaire est rattaché à l'un de ces super pairs. Les fichiers partagés par un noeud ordinaire sont listés sur le super pair responsable de ce dernier, jouant le rôle de "mini" serveur d'index. Mais, contrairement à un serveur centralisé, un tel serveur reste un noeud standard (typiquement l'ordinateur personnel d'un particulier) et n'est pas un serveur dédié. Lorsqu'un utilisateur recherche un fichier, une requête est envoyé à son super pair. Si celui-ci ne trouve pas le nom de ce fichier dans son index, il renverra la requête à d'autres super pairs voisins. Cette façon de procéder a été introduite par FastTrack, un protocole de peer-to-peer implémenté dans plusieurs logiciels tels que KazaA ou Morpheus.
Ces trois approches vous permettent d'avoir une idée plus précise du fonctionnement du peer-to-peer, dont les techniques et protocoles sont bien évidemment en constante évolution. Le sujet mériterait également que l'on aborde les questions d'ordre juridique et éthique, mais ce n'est pas mon but aujourd'hui.
Conclusion
Nous voilà donc arrivés au terme de cet article relativement long! J'espère qu'il vous aura permis de vous faire une idée plus précise de ce qu'est Internet et de son fonctionnement ainsi que de ses applications.
, le 10.01.2008 à 01:55
Et bien oui, superbement réalisé. Je l’ai gardé bien au chaud.
, le 10.01.2008 à 08:05
Décidément, très beau travail. Merci 6ix.
Un conseil : copiez et collez les deux URL ci-après dans un message destiné à ceux de vos amis qui se posent des questions sur l’Internet :
Cuk.ch – Internet: un réseau de réseaux
https://www.cuk.ch/articles/3620
Cuk.ch – Internet: les applications importantes
https://www.cuk.ch/articles/3533
Il en ressortiront moins niais et vous ferez plaisir à l’équipe de CUK. Deux bonnes actions d’un coup ;-)
, le 10.01.2008 à 08:26
magnifique travail…
j’en ressort bien moins niais :o)
, le 10.01.2008 à 08:52
Je confirme, parfait.
Attention, Basile et Juliette communiquent oralement pour l’instant. Je précise que ma fille n’a pas d’e-mail (pour l’instant)!:-)
Les exemples pris dans l’article ne sont donc que de la pure fiction, je ne suis pas un monstre.:-)
, le 10.01.2008 à 09:17
François, tu ne sais pas tout ce qui se passe dans ton dos quand tu surveilles les poussières sur tes capteurs ;°)
, le 10.01.2008 à 09:24
Merci encore pour la deuxième partie de cet article. Je continue néanmoins à me poser des questions…
Comment certains gouvernements, tels les chinois, coréens et autres “démocrates” patentés, s’y prennent-ils pour brider les accès à internet?
Et par là même est-il possible de brider le réseau au niveau mondial, voire de le mettre HS ? J’ai bien compris que physiquement le réseau avait par essence la capacité de s’adapter aux différents “tuyaux” et à leur état, mais, est-ce un excès de paranoïa, peut-on prendre le contrôle de ce système et ouvrir ou fermer des “portes” comme bon semblerait à celui qui l’aurait décidé ?
Aujourd’hui, tout passe, tout transite, et même le NSA américain semble peiner à voir ce qui se passe… Est-ce inhérent aux protocoles, aux liaisons physiques ou à autre autre chose ? Peut-on imaginer demain une panne d’internet à l’échelle mondiale ?
, le 10.01.2008 à 09:56
Fa-bu-leux ! Vraiment !
, le 10.01.2008 à 10:05
Le maillage du réseau n’est pas si fin que celà et les entrées/sorties (ie les tuyaux par lesquels transitent l’information) d’un pays vers un autre peuvent être assez facilement contrôlés et d’autant plus par des pays tels que la Chine ou la Corée du nord où les infrastructures sont contrôlées par le pouvoir (et les fibres optiques en font partie). Paralyser la communication entre des grands blocs régionnaux (Asie/Amérique par exemple) n’est pas si difficile que celà => les liaisons océaniques par fibres peuvent se saboter (bon, ce n’est pas à la portée du premier pékin venu …). Il me semble d’ailleurs que récemment un ensemble de câbles marins a été endommagé par un phénomène naturel (tremblement de terre ?) et que celà a créée une belle pagaille en Asie. Un des autres moyens de paralyser le système est de s’attaquer aux serveurs DNS racines qui sont tous localisés aux USA => en cas de mauvais fonctionnement de ces serveurs, le traffic serait sérieusement perturbé. Mais j’imagine qu’ils doivent être un tant soit peu protégés … On peut également présumer que des gouvernements ont des plans tous prêts pour mener une guerre électronique sur Internet => certains pays occidentaux ont fait état de manoeuvres bizarres, en provenance à priori de Chine, visant à tester/perturber les infrastructures réseaux des pays visés. Il y a eu débat au sénat américain à propos de ces “attaques”. Bref, en cas de conflit, la probabilité pour qu’Internet saute est, à mon avis, forte voir très forte.
, le 10.01.2008 à 12:53
Juste une petite précision sur les DNS :
Effectivement, les DNS “racine” sont une pierre angulaire de l’internet, si ils tombent, on peut presque considérer que internet tombe (presque). Mais ils ne sont pas tous aux US ! Ils sont au nombre de 13 actuellement, gérés par différentes entités, et répartie géographiquement. De plus, certain serveurs ne sont pas constitués de juste une machine. Par exemple, le serveur F est réparti en 43 points, que vous pouvez voir à cette adresse :
http://www.isc.org/index.pl?/ops/f-root/
Le serveur M, lui, utilise deux machines avec deux machines de backup :
http://m.root-servers.org/
Dans le principe, les DNS mondiaux ne connaissent pas tout le monde, mais connaissent les serveurs qui connaissent. Il y a des milliers de serveurs dns sur internet, qui gèrent chacun leur domaine (il y en a un qui gère cuk.ch par exemple). En plus de ça, les DNS mémorisent les informations qu’ils demandent aux autre DNS pour une certaine période. Ainsi, si une demande arrive sur un serveur DNS et qu’il ne peut pas y répondre, il demande à son DNS de référence, et ainsi de suite, jusqu’a, éventuellement, demander aux DNS mondiaux. Lors de la prochaine demande, il connaîtra la réponse, et la retournera directement.
Cette organisation permet de répartir l’information, et donc de soulager la charge des dns mondiaux. Si tous les serveurs étaient bien configurés, leur charge serait presque nulle.
Mais ça ne fait pas tout : il y a eu, en 2002, une grosse attaque en déni de service sur ces machines, qui à fait tomber 7 serveurs. Plus récemment, il y a eu une tentative en Février 2007, mais qui n’a eu presque aucun effet : l’attaque précédente avait servi de leçon.
Donc, au final, oui, les DNS mondiaux peuvent être considérés comme un point faible de l’internet, mais je ne me fait pas trop de soucis, c’est pas demain que tout s’écroulera.
, le 10.01.2008 à 13:27
Merci pour ce deuxième volet, 6ix!
Tu te destines à l’enseignement, j’espère! N’hésite pas autant que Fabien! ;-)
Milsabor!
, le 10.01.2008 à 14:03
Merci bien!
Tout à fait, d’ailleurs je compte reprendre cet article demain pour un cours à l’école enfantine! ;-) Non plus sérieusement, ce n’est pas mon envie (pas d’hésitation donc), mais l’idée de donner des cours “annexes” de temps à autre sur une matière que je maîtrise me plaît assez. On en reparle d’ici quelques années!
, le 11.01.2008 à 13:29
Si l’enseignement ne te tente pas, tu peux essayer de rédiger des règles du jeu. On trouve dans les boites des règles parfois confuses ou mal ordonnées. Tes deux articles montrent que tu sais ranger les sujets et surtout bien répartir la qualité de ton information : chaque sujet abordé est équitablement traité, sans débordements. Les règles du jeu se doivent d’êtres claires et sans ambiguïtés. Les tournures de phrases et le vocabulaire employé nécessitent rigueur et organisation (ce qui est donc très différent de la littérature). Une fois les règles du jeu bien maîtrisées, il n’y a qu’un pas pour devenir législateur. Les lois ne sont rien d’autres que les règles du jeu de la société. Et nous savons tous qu’une loi mal rédigée se contourne trop facilement et peut même devenir néfaste.
Un blog à propos de la juridiction française : http://www.maitre-eolas.fr/ L’auteur est prolifique, parfois partisan, mais toujours riche d’enseignement. Je le cite ici car il m’apporte régulièrement le même plaisir que la lecture des deux articles de 6ix.
, le 11.01.2008 à 14:25
Bonjour,
J’ai parcouru ton article (question de temps). Il semble qu’il y ait un oubli de taille : le protocole NNTP sur lequel repose Usenet (sorte de forum mondial organisé par thèmes). Ce protocole doit être aussi ancien que celui utilisé pour l’e-mail et bien qu’on en entende peu parler il est toutefois extrêmement utilisé.
Pour l’anecdote, il faut noter que Usenet a longtemps servi aux utiliseurs de Free comme outil de diffusion/téléchargement illégale de musique, vidéo, logiciel : l’absence de bruit autour de ce protocole permettait (et permet encore apparement) d’échanger des binaires en toute tranquilité, d’autant plus que certains hébergeurs proposent des connexions cryptées.
Depuis, Free a été contraint de fermer le robinet de certains groupes de nouvelles (ou news groups selon l’appellation courante).
Malgré tout, il existe toujours une très forte activité sur les serveurs NNTP de part le monde.
K. (p.s. navré pour les fautes d’ortho).
, le 13.01.2008 à 11:01
Formidable, j’ai encore appris plein de trucs, et surtout, cet article clarifie bien les choses.
Merci, 6ix!
z (faut pas s’endormir, avec les “technologies de l’information”, je répêêêêête: sinon, on est vite largués)