
Les programmes de reconnaissance de caractères (ROC en français, OCR en anglais) sont pour moi, depuis leurs débuts, des outils un peu magiques que j'ai toujours appréciés, au point de passer sur Mac depuis Atari, rien que parce que sur cette dernière plateforme, rien d'efficace n'existait à ce niveau.
Pensez: ces logiciels lisent véritablement le texte que vous leur soumettez via un scanner, un appareil de photo numérique, et hop, ils vous retapent tout ça à la vitesse de l'éclair dans votre programme préféré avec désormais bien peu de fautes.
J'aimerais juste être très clair: après avoir passé un texte quelconque à la moulinette d'un OCR, vous pouvez changer des mots, retravailler le texte, à la grande différence d'une photocopie.
J'ai écrit déjà de nombreux articles à propos ces programmes de reconnaissances à l'époque dans différents journaux, puis sur Cuk.ch.
Par exemple, OmniPage X, testé ici. Manque de bol, ce programme a été abandonné comme une vieille chaussette et scandaleusement par son éditeur.
OmniPage, vous devez oublier absolument.
Puis j'ai testé ReadIris Pro 9 , de la société belge IRIS qui était à l'époque une bonne alternative.
L'article que vous lisez en ce moment est une mise à jour de ce dernier, entièrement dédiée au tout nouveau ReadIris Pro 11, testé ici en version 11.05, parfaitement compatible avec mon scanner Epson, mais avec bien d'autres aussi, pour autant qu'ils soient eux-mêmes compatibles avec la norme TWAIN, ce qui est généralement le cas. Le programme supporte également les fichiers TIFF ou JPEG sortis d'appareils de photo.
Mieux même, comme nous allons le voir, il reprend vos documents PDF en respectant au mieux la mise en page. Ce n'est pas de la pub, c'est la réalité…
ReadIris est passé de la version 9 à la version 11 sans passer par la 10. Pour une fois, nous sommes même en avance, au moment où j'écris ces lignes, sur la version PC qui en est restée à la 10. Incroyable!
Les progrès sont-ils à la hauteur?
Et bien ma fois oui, et ReadIris, qui était déjà très bon, est désormais très proche de la perfection, comme nous allons le voir.
Une interface efficace
ReadIris 11 reprend l'interface, aérée, esthétique et véritablement simple à utiliser qui avait été inaugurée dans la version 9.
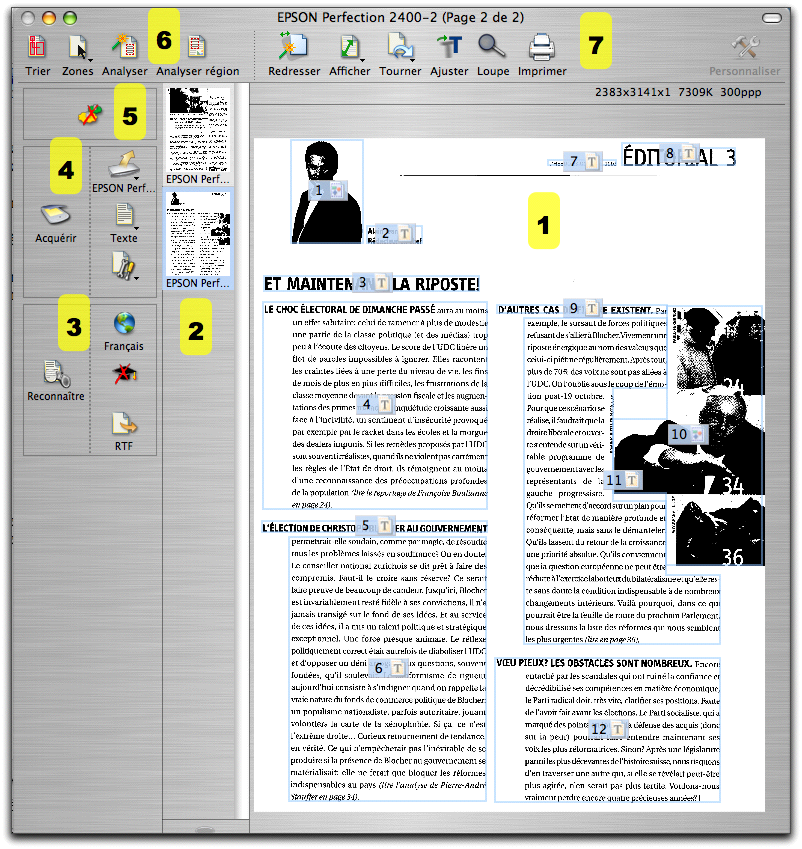
- la zone du contenu de votre document, ici après numérisation;
- la zone des pages numérisées et reconnues;
- la zone des réglages de base (langue, type d'apprentissage);
- la zone de choix du document si déjà existant ou d'acquisition via un scanner;
- le choix du mode tout auto ou non;
- la zone de préparation du document (choix de traçage des zones à reconnaître);
- la zone d'amélioration du document si besoin est (redressement, nettoyage);
Comme vous le voyez, si tout est réglable via des menus traditionnels, la plupart des fonctions sont paramétrables via des boutons parlants ou un clic de souris. La barre d'outils est entièrement paramétrable, comme le sont toutes les applications cocoa. Et visiblement, ReadIris en est une.
Ah, petit détail important pour certains: si l'alu brossé vous insupporte, vous pouvez demander au programme de ne plus l'afficher…
Tout commence par les réglages dans la zone 4 de la fenêtre. Il faudra choisir ce qui va être reconnu: un fichier (sous forme d'image ou PDF) ou, s'il faut numériser, le scanner qui va se charger de ce travail.
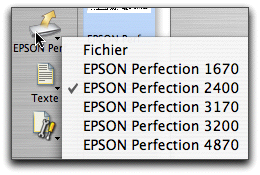
Seuls quelques scanners Epson sont installés sur mon disque…
Toujours dans cette zone de paramétrage, on choisit ce qui va advenir de notre reconnaissance:
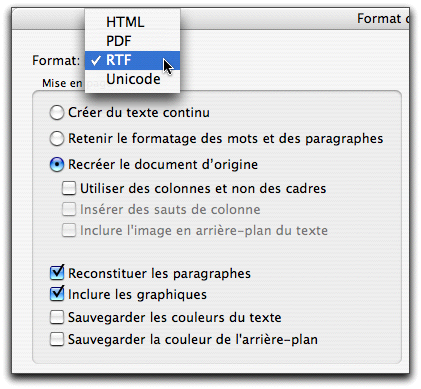
Comme vous le constatez, les formats importants sont présents, nous reparlerons du PDF et du HTML plus bas.
ReadIris vous propose également d'ouvrir, pour chaque format, une application dans laquelle vous verrez le résultat de la reconnaissance:
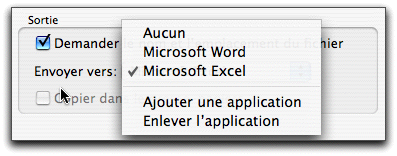
Ici, le logiciel fait preuve d'intelligence. Pourquoi vouloir réinventer la roue et montrer le résultat dans un éditeur "maison", comme le fait par exemple OmniPage? Iris a plutôt choisi d'ouvrir automatiquement l'application dans laquelle vous travaillez, avec tous ses outils de correction, ménageant ainsi vos petites habitudes.
On peut choisir de travailler de manière automatique: une fois que l'on appuie sur la zone acquérir. et que l'on aura défini via l'interface du scanner, quoi numériser, ReadIris prend tout en mains, jusqu'à la sortie sur le programme désiré.
Personnellement, je ne le recommande pas.
Tous les outils pour bien préparer sa reconnaissance
Pour assurer une bonne reconnaissance, il vaut mieux que la numérisation soit au top, ou pour le moins la meilleure possible. Une résolution de 300 points par pouce est recommandée, 400 si le texte est très petit.
Il se peut que notre document n'ait pas été introduit bien droit dans le scanner, ou que des taches soient apparues. Le redressement et le nettoyage peuvent être automatiques (ce qu'ici je recommande) ou manuel, via les zones dédiées (7).
Les différents outils disponibles pour préparer la reconnaissance…
enfin, une partie, la suite arrive!
Pour pallier ces problèmes, ReadIris 11 propose quelques options bien pratiques, comme un redressement de la page extrêmement efficace, une détection automatique de l'orientation qui l'est tout autant, et une suppression du bruit qui fait tout ce qu'elle peut, mais qui n'est pas capable de faire des miracles sur un document trop détérioré.


Avant, après redressement…
Et puis, vous pourrez laisser le programme choisir tout seul les zones à reconnaître. De manière automatique, ReadIris sait quand nous avons à faire à une zone de texte, une zone graphique ou un tableau.
L'analyse d'une page complexe est assez exceptionnelle, et le logiciel reconnaît souvent de manière très correcte le sens de lecture, ce qui est pourtant loin d'être évident.

L'original (L'Hebdo)

L'analyse faite par ReadIris

Reconnaissance et export dans Word. Magnifique non?
On continue avec un nouvel exemple, toujours tiré de l'Hebdo.

L'original…


La sortie finale dans Word. Il y a juste le dernier bloc de texte à glisser légèrement…
Néanmoins, je préfère parfois choisir de sélectionner les zones de manière manuelle. Il suffit pour ce faire de tirer des rectangles sur la zone scannée présentée à l'écran.


Chaque zone peut être affublée de l'attribut texte, tableau, graphique, voire même code-barres désormais ou zone de texte manuscrite. Il est possible de changer l'ordre des zones à reconnaître à tout moment (voir ci-dessus).

De plus, il est possible de créer des zones irrégulières en faisant simplement se chevaucher deux zones!

Pour faciliter notre travail, différents zooms sont possibles, et une loupe permet de se rendre compte de la qualité de la reconnaissance. C'est bien réalisé et agréable.

C'est aussi beau que dans Aperture!
Il est encore possible, en cas de document difficile, d'indiquer à ReadIris quel type de caractères composent notre page.

Si vous avez plusieurs documents de même type, composés de la même manière (par exemple un livre dont vous désirez supprimer les hauts et bas de page), vous pouvez sauver votre découpage de zones pour le réutiliser plusieurs fois.
Lorsque nos pages sont numérisées, elles sont stockées et atteignables dans une zone située entre les outils et la fenêtre du document. Un clic sur une vignette affiche la page correspondante.
Une option supplémentaire est disponible: reconnaissance à partir d'un appareil de photo. Le logiciel pourra corriger un manque de netteté dans certaines zones du document, si votre appareil n'était pas bien à niveau par rapport au document ou se satisfaire d'une résolution plus basse.
Ok, c'est faux, l'Epson n'est pas une caméra numérique, c'est juste pour montrer…
Les langues, et elles sont nombreuses!
ReadIris 11 reconnaît toutes les langues européennes (y compris d'Europe Centrale et Baltique, ainsi que le grec et les langues cyrilliques), ainsi que les langues américaines. Vous en voulez plus? Des options existent: les langues asiatiques (chinois simplifié, chinois traditionnel, japonais et coréen) ainsi que l'hébreu.
En ce qui nous concerne, le français est parfaitement reconnu avec ses accents et cédilles si particuliers. Il n'y a vraiment aucun problème.
Plus même, ReadIris peut reconnaître du texte en plusieurs langues. Au cas où vous feriez une reconnaissance de texte contenant par exemple du français et de l'anglais, il vaudrait mieux choisir la langue française comme langue de reconnaissance, justement pour que les accents ne posent pas de problème particulier au logiciel. Les mots anglais seront reconnus sans problème. ReadIris passe d'une langue à l'autre automatiquement.
Le panneau des langues: 120 sont disponibles hors option, plus une, la police numérique si vous savez ne devoir reprendre que des chiffres dans un tableau, afin d'éviter les erreurs.
Un apprentissage interactif si jamais…
Imaginez que vous ayez un document important, comportant de très nombreuses pages à reconnaître. Imaginons toujours que le "l" (lettre L en minuscule) soit toujours reconnu comme un "1" (un). Et que le "e" soit reconnu comme un "c". Dans tout le document…
L'horreur!
Et bien, avec ReadIris, aucun problème puisque vous pouvez demander un apprentissage interactif des caractères.
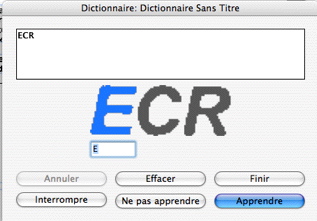
Vous pourrez sauver cet apprentissage dans un dictionnaire spécifique que vous rappellerez chaque fois que vous avez un document de même type à reconnaître.
Et les résultats?
Les résultats? Ils sont très bon, vraiment. Prenons quelques exemples:
Reconnaissance d'une circulaire sortie d'une imprimante laser: incroyable! Moins de trois secondes après avoir lancé la reconnaissance (hors temps de numérisation), tout est repris de manière pratiquement parfaite, y compris les styles et l'alignement des paragraphes. Il n'y a aucune erreur la plupart du temps. Parfois, une espace en trop ou en pas assez.
Reconnaissance de la même page passée dans un fax, pour voir ce que le logiciel est capable de faire avec de mauvais documents: et bien il fait pratiquement aussi bien! Il y a un" i" qui est deux fois pris pour un "t". Un petit passage par Antidote, ProLexis, ou même le correcteur intégré à Word nous indique immédiatement ces erreurs. Ici, ReadIris change trop souvent de polices, mais là également, il s'agit de sélectionner le texte et de lui donner une police pour que tout soit résolu.
Reconnaissance d'un texte sorti d'un quotidien (24H) donc sur papier journal de piètre qualité.


À gauche, la page originale, à droite, la même, reconnue dans Word (sans garder la mise en page)
ReadIris a oublié une espace, et fait quelques changements de taille de caractères intempestifs. Il a eu un peu de peine à reconnaître les "20 000 lieues", remplaçant "20 000" par "20 () () ()". Un S a été remplacé par un $. Le chevron du départ (à gauche de Hollywood) n'est pas reconnu non plus, ce qui est tout de même normal.
Et il faut voir que le journal était bien plus grand que mon scanner, que le texte de départ était penché, et c'est ReadIris qui a tout redressé avec ces petits doigts!
Une page d'un hebdomadaire, l'Hebdo, sur papier glacé.
Les deux exemples tirés de l'Hebdo, montrés plus haut, donnent des résultats étonnants. Comme pratiquement tout ce qui est imprimé sur ce type de revues d'ailleurs.
Dans certains cas, j'ai délibérément choisi de laisser tomber certaines zones. Il peut en effet arriver que ReadIris prenne en effet la découpe de la page pour des zones graphiques, autant ne pas le perturber avec ça.
Il m'a suffi de cliquer dans l'ordre sur les zones que je voulais reconnaître (en utilisant ce que ReadIris avait fait comme découpage).
Là encore, le résultat est excellent. Quelques mots mal séparés, vite repérés grâce à nos outils de correction, aucune faute d'orthographe.
Enfin, si le texte est écrit sur des encadrés colorés, la reconnaissance est tout aussi bonne.
Les tableaux
J'ai testé ReadIris sur toutes sortes de tableaux. Là encore, pour autant qu'on lui ait spécifié qu'il s'agissait d'une zone de tableau, les résultats sont très bons. Mieux même, puisque c'est même le cas très souvent sans rien dire au logiciel, depuis cette version 11.

Les cellules sont divisées en deux en largeur, et il y a une espace à rajouter dans le titre.
Sinon, c'est assez grandiose vous ne trouvez pas?
Les tableaux les plus compliqués sont repris de manière presque parfaite. Les cellules fusionnées dans l'original sont rendues de même manière en sortie. Par contre, il faut parfois lier certaines cellules entre elles. En effet, ReadIris prend de temps en temps chaque retour de ligne pour une nouvelle cellule. Pour le reste, c'est tout bon.
La reconnaissance de fichiers PDF
Reconnaître des fichiers imprimés, c'est bien, mais à notre époque, pouvoir reprendre de la même manière un fichier PDF, c'est mieux!
Et c'est ce que sait très bien faire ReadIris Pro 11.
J'ai par exemple donné au programme le manuel du parfait petit citoyen devant remplir sa déclaration d'impôts.
Voyez plutôt!
Mais bon, la reconnaissance d'un PDF pour obtenir un PDF n'étant pas très utile (quoique, voir plus bas), voyons ce que cela donne au niveau résultat RTF dans Word.
Je constate que si la page 2 par exemple est excellente au premier abord, il va être difficile de l'éditer puisque les blocs créés ne correspondent pas forcément au texte de départ (tableau en particulier).

J'ai donc simplement préféré tracer mes zones, en indiquant à ReadIris où étaient les tableaux. Ce travail est effectué en quelques secondes!

C'est nettement mieux n'est-ce pas? Même si j'aurais préféré que ReadIris ne crée
pas une cellule surnuméraire dans certains cas.
Il est dommage que dans certains cas, certaines illustrations qui devraient être comprises comme telles par le programme soient vues en fait comme du texte. Il vaudra ici également mieux tracer ses zones à la main, en cas de document un peu complexe.
Dans tous les cas, sur un MacBook Pro, alors que le programme n'est pas encore optimisé à l'heure où j'écris ces lignes pour Macintel, comptez 10 secondes par page A4 pour le chargement et l'analyse, puis 4 secondes pour la reconnaissance.
Reconnaissance de documents manuscrits?
Lors du traçage des zones, une petite option est venue me titiller:
Regardez la deuxième ligne…
Le programme serait-il capable de reconnaître mon écriture délicieuse?
Je fais très vite un petit essai en écriture liée (style instituteur, un peu bébé) et le résultat est proche du néant.
Je vois ensuite dans l'aide que l'écriture manuscrite liée n'est pas reconnue par le logiciel, mais qu'il faut séparer les lettres. Seuls les chiffres et les lettres majuscules (sans accent) sont supportées, et ce grâce à la technologie embarquée ICR qui signifie “Intelligent Character Recognition”.
Voyons ce que ça donne…


Oui bon, bôf… ReadIris propose une grille de base pour être sûr d'écrire
droit et avec un espacement régulier.
Le programme reconnaît par contre certaines polices de type "script". Pas toutes dirons-nous, voyez plutôt cet exemple en Lucinda Handwriting:


D'autres polices passent mieux, mais bon, ce n'est tout de même pas la tasse de thé de ReadIris, ces polices spéciales.
Généralités
La reconnaissance, comme vous venez de le voir, est très bonne, hors polices spéciales. Il faut noter que l'italique est bien luégalement alors que cette déclinaison d'une police a été longtemps une source d'énormes problèmes pour les OCR.
Parfois, il vaudra mieux demander de ne pas reconstituer le document original au niveau de la mise en page. En effet, ReadIris s'en sort bien, mais c'est dans Word que les problèmes se posent. La plupart du temps, la reconnaissance des styles est largement suffisante et facilite l'édition après coup, en évitant les blocs de texte pas toujours faciles à gérer.
L'export
Comme je l'ai écrit plus haut, une reconnaissance peut donner un document texte, RTF, mais aussi PDF et HTML.
En effet, ReadIris sait lire les formats PDF, mais également en créer, avec signets s'il vous plaît. Pour ce faire, il se base à la fois sur les images et sur les titres des paragraphes, à ce que j'ai pu constater.
J'ai même pu prendre un manuel au format PDF qui ne disposait pas de signets, le faire reconnaître par ReadIris, et lui demander de ressortir le même fichier mais avec les signets cette fois. Rigolo… Même si parfois les signets sont un peu aléatoires il me semble.
Au niveau HTML, nous obtenons des fichiers parfaitement lisibles par Safari (ici, une page du catalogue de l'Université Populaire de Lausanne) même s'il m'est arrivé parfois d'avoir une page blanche comme résultat, je ne sais pas pourquoi. On redemande l'export et tout rentre dans l'ordre.

Une page d'un recueil d'activités parfaitement reconnue, mise en page comprise. Juste un "il" qui devient un "II"
En conclusion
Vous avez compris que ReadIris Pro 11 est un excellent logiciel de reconnaissance de caractères. Le meilleur je pense à l'heure actuelle, ce qui au passage n'est pas trop difficile, vu que la concurrence est pratiquement inexistante. Tant pis, celui-là va très bien.
De plus, ReadIris est souvent mis à jour (preuve en est, la version 11.05 disponible relativement peu de temps après la sortie de la 11.0).
Si ce programme n'est pas encore Universal Binary au moment où j'écris ces lignes, il est à noter qu'il tourne à merveille sous Rosetta, et que vous pouvez par conséquent parfaitement l'utiliser sur Macintel, qu'on se le dise!
Vous l'avez compris, mon choix est fait. S'il faut vous en conseiller un, c'est ReadIris 11, c'est clair, même si le prix de 499 $ peut faire réfléchir celui qui n'a pas forcément besoin de ce logiciel, et d'ailleurs même celui qui en ferait un grand usage.
Cela dit, il vous évitera peut-être des dizaines d'heures de saisie, et ça voyez-vous, ça a un prix aussi et la chose devrait être assez vite rentabilisée.
, le 28.03.2006 à 08:21
Hum, oui, 499 $, ça ferait tousser mon compte en banque :-( Ceci dit, ce genre de logiciel m’apparaîtra toujours un peu… magique !
, le 28.03.2006 à 08:31
C’est le genre de logiciel à acheter avant de se marier, ça, la reconnaissance de caractères…
, le 28.03.2006 à 08:36
Je viens de faire un tour sur leur site, et ne trouve aucune offre de mise à jour, leur écrire tient un peu de la gageure. Ayant dépensé pas mal de fric pour la version 9, je ne voudrais pas recommencer sur la 11… Comment faire docteur? Quelqu’un a une suggestion sur la mise à jour? Le site Iris n’en donne aucune. Ai-je manqué quelque chose?
Anne
, le 28.03.2006 à 08:58
Pour Anne :
http://www.irislink.com/c2-73/Readiris-Pro-11-Mac.aspx
Ça peut aider ?
, le 28.03.2006 à 09:30
Pourquoi payer une fortune quand il existe des solutions gratuites pour Mac et Linux ?
J’ai téléchargé récemment ce logiciel, mais ne l’ai pas encore testé à fond.
C’est par là : DigitEye OCR et c’est en français !
Alexis
, le 28.03.2006 à 09:35
languedoc: merci, oui! J’avais donc manqué quelque chose… ;-)
Mais pour une mise à jour, c’est le coup de fusil!
Anne
, le 28.03.2006 à 11:02
On me signale ceci:
http://www.valcenter.ch/product_info.php?products_id=6421
Je n’y comprends rien! c’est moins cher que le prix de la mise à jour signalé plus haut!
, le 28.03.2006 à 11:18
Moi cela fait un peu plus d’une année que j’ai décidé de mener une guerre totale à la paperasse au sein de mon entreprise. Tout document provenant de l’extérieur qui passe le premier tri à l’ouverture du courrier, est systématiquement scanné et stocké en .pdf sur notre serveur. Les documents sortants sont évidemment archivés dans leur format original, (Word, Exel, .ai, etc.). Seuls les contrats d’une certaine importance sont classés physiquement pour cause de signature originale.
J’utilise le soft livré avec mon scanner, soit CanoScan Toolbox X. Et bien simplement en choisissant l’option « PDF indexable » et langue « français », les documents PDF créés ne sont en fait pas de simple images, mais du texte (quand c’est du texte), permettant à Spotlight de trouver une occurrence dans le document. Et ça croyez-moi c’est vraiment génial ! Par exemple Spotlight est capable de me retrouver en quelques secondes toutes les factures fournisseurs et les bulletins de livraison concernés par un nº d’article enfoui au sein des documents scannés. Pour moi, le classeur fédéral, c’est l’âge de pierre ! Et toutes les administrations (fiscale par exemple) acceptent cette solution d’archivage.
Précédemment, l’administration de mon entreprise engendrait une bonne quinzaine de classeurs fédéraux par année. Multiplié par les 10 ans durant les lesquels nous devons légalement conserver nos documents, je vous laisse calculer le gain de place et de praticité.
Bon, j’ai débordé un brin du sujet original, mais pas tant que ça après tout. Il s’agit bien de numérisation de documents papiers. Je voulais juste souligner que selon son cahier des charges, il n’est pas forcément nécessaire d’acquérir un logiciel aussi sophistiqué que celui testé par François.
, le 28.03.2006 à 12:03
alec6, je sais, on m’avait déjà signalé DigitEye lors du test de ReadIris 9. Le problème, c’est qu’il en avait justement, et que si tu regardes leur site, la dernière nouvelle date de 2004!
Pas vraiment envie d’essayer à nouveau!
, le 28.03.2006 à 12:44
Omnipage existe encore , mais ne semble plus évoluer…
, le 28.03.2006 à 12:54
What about Adobe Acrobat ? Qui propose également une reconnaissance OCR vraiment impressionante pour le prix… d’Adobe Acrobat !
, le 28.03.2006 à 13:12
J’utilise la version 9. Quelles sont les plus-values / fonctionnalités apportées par cette version 11 qui justifieraient de faire une mise à jour à 150 € ?
, le 28.03.2006 à 14:55
Voici la fonction qui manque reellement dans les programmes OCR: le redressement de pages de livre. Je m’explique. Ma femme faisant une these en histoire a besoin de consulter enormement d’archives. Or il n’est souvent pas possible de faire de photocopies des documents et livres (pour toutes sortes de raisons). Donc elle a pris des photos des pages avec son appareil numerique. Seulement voila, quand on prend une photo d’une page de livre sans vouloir l’abimer, le texte est « bombee » vers la reliure. A cause de cela, elle ne peut pas utiliser de programme OCR, car la courbure des lignes empeche les OCRs de fonctionner correctement. Il manque une fonction de redressement ou l’on pourrait manuellement (ou automatiquement) indiquer la courbe a suivre pour redresser le texte. D’ici la, bein y’a pas de solution viable pour elle.
, le 28.03.2006 à 15:19
499$ ? Comprends pas, j’ai payé la version 11 que j’ai achetée à sa sortie 80 € !!! Vérification faite, à ce jour, elle coûte environ 110 € ! La version Corporate, elle, coûte plusieurs centaines d’euros/dollars, oui.
Sur le fond, il faut que je prenne du temps pour lire l’article de François car, de mon côté, je ne suis pas toujours très satisfait de la qualité d’analyse.
Jean-François
, le 28.03.2006 à 15:47
Tu as oublié de parler d’une possibilité intéressante :
Reconnaissance des cartes de visite
Numériser et reconnaissez vos cartes de visite et exporter les contacts ainsi créés vers votre gestionnaire de contacts préféré (Carnet d’Adresses, Entourage, AppleWorks, NowContact, etc.)
Vous pouvez sauvegarder vos cartes de visite en fichier vCard ou HTML (avec l’image de la carte numérisée inclue) ou créer un fichier texte structuré pour l’importation dans toutes bases de données de contacts
Readiris synchronise aussi Carnet d’Adresse avec votre iPod et téléphone portable.
J’ai la version 9, je crois que je vais y passer :-)
, le 28.03.2006 à 16:46
Le meilleur locigiel de OCR est sans l’ombre d’un doute FineReader… pour Windows.
, le 28.03.2006 à 17:20
499 dollars? Même prix qu’Aperture. Ca doit être l’effet « loupe » :)
, le 28.03.2006 à 20:07
Je m’excuse, mais les prix sont ici:
http://www.irislink.com/c2-167/Price-List-Readiris-for-Mac-OS.aspx
ReadIris Pro upgrade 129.99 $
ReadIris Pro Corporate Edition: 499.99 $
Je ne peux pas dire qu’il faut acheter un upgrade à la place d’une version pleine tout de même! Si vous voulez le faire, libre à vous (il semble que ça fonctionne), mais je me dois de donner le prix réel.
Il faudrait une bonne fois qu’IRIS soit clair avec ses prix…
, le 28.03.2006 à 20:28
Gasp, presque 500$… heureusement qu’il existe sur le store édu d’Apple pour « seulement » 219 francs suisses :-)
, le 28.03.2006 à 22:20
Et voilà! Encore un autre prix…
Incroyable, je n’ai jamais vu ça…
, le 28.03.2006 à 22:24
Pas besoin de t’excuser, François.
Je voulais simplement signaler que 499 $, c’était le prix de la Corporate Edition. La version standard est à un peu plus de 100 € (pas une mise à jour). C’est celle que jai achetée auprès d’un revendeur il y a quelques semaines.
Jean-François
, le 28.03.2006 à 22:34
J’ai eu besoin d’OCR pour récupérer pas mal de données en tableau sans avoir à les resaisir.
J’avais OmniPage sous OS9.
Il ne se trompait pas trop, juste 1% de doute, sur environ 6000 signes par page. Ce n’étaient pas des mots, mais des nombres…Non pas qu’il hésitait, mais donner un « sept » pour un « un », ça fait mal.
j’ai failli le bouffer.
, le 29.03.2006 à 09:50
Mais je suis désolé, lorsque je lis « Upgrade », pour moi ce n’est pas une version pleine.
Encore une fois, on trouve tous les prix sur ce produit. C’est un peu n’importe quoi à ce niveau.
, le 29.03.2006 à 11:59
Il y a 2 éditions : Pro et Corporate. La Corporate ajoute des fonctions avancées comme le traitement par lot (batch processing), le support des scanner duplex, etc. Voir « Additional features to the Pro edition » sur la page produit de la version Corporate. Et ça coûte 500 $.
La version Readris Pro 11.0 Mac VF, y.c. frais de port :
– 91 € chez Graphiland.fr (108 € pour la Suisse, soit 170 CHF)
– 99 € sur FNAC.com (108 € pour la Suisse, soit 170 CHF)
– 149 € sur AppleStore (219 CHF en Suisse)
Effectivement le moins cher c’est chez ValCenter (135 CHF), mais je ne sais pas si les frais de port sont inclus.
, le 29.03.2006 à 13:21
azuff, ce sont visiblement des revendeurs qui vendent à vil prix des mises à jour, désolé, pour moi, le prix de l’éditeur reste jusqu’à nouvel avis celui que je donne sur ce site.
Readiris Pro 11 Mac Upgrade
International: EUR 152
North America: USD 129,99
Maintenant, vous avez raison si vous achetez chez ces revendeurs, mais il faut simplement être clair.
, le 30.03.2006 à 12:08
Communiqué de presse IRIS du 23 février (9 pages):
page 1 :
IRIS introduces Readiris Pro 11, the new version of its flagship product for text recognition (OCR) and ReadIris Pro 11 Corporate Edition, the professional version of IRIS OCR.
70+ new improvements and major features
[…]
page 8:
Macintosh versions (suggested price, incl VAT)
Readiris Pro 11 : 149 €
Readiris Pro 11 Corporate edition : 499 €
Comme par hasard, l’Apple Store propose le logiciel à 149 €.
, le 31.03.2006 à 15:42
Je viens témoigner en faveur de Omnipage Pro X que j’ai acheté à sa sortie pour (si ma mémoire est bonne) 99$.
Je regrette bien sûr son manque d’évolution, mais il continue de marcher sans aucun problème chez moi (Macmini, OS X.4.5).
A sa sortie, j’ai testé Readiris Pro 11, et j’ai eu de bien moins bon résultats, beaucoup plus d’erreurs de reconnaissance. C’est peut-être dû au type de documents que j’ai à traiter en permanence: des textes mathématiques avec des occurences fréquentes de lettre grecques, d’indices, d’exposants. Aucun des deux ne reconnait d’ailleurs ces détails particuliers, à mon grand dam. Par contre, je n’ai pas tellement le besoin de reconstituer les formats d’un texte. Je les reformatte toujours moi même selon les besoins.
Du point de vue ergonomie, les deux se valent à peu près, mais je trouve le workflow de Omnipage plus efficace. C’est peut-être une question d’habitude.
J’ai donc été déçu par ReadIris Pro 11, et je suis revenu à OmniPage Pro X que je trouve nettement plus satisfaisant.
A+
Jean-Denis
, le 13.04.2006 à 14:30
J’ai acheté hier ReadIRIS 11 pour 139 francs suisses dans un magasin tout à fait ordinaire. Pas une mise à jour: le soft lui-même, dans une boîte avec brochure. 139 francs suisses, cela fait 92-94 Euros. IRIS me bombarde de mails depuis quelques jours pour me proposer une mise à jour de ReadIris 9 au prix spécial de 99 Euros (150 francs suisses), dans une semaine le prix sera de 150 Euros (225 fr. suisses). Sur leur site, le programme neuf est proposé à 499$ et la mise à jour à 190$ il me semble (je ne me souviens plus précisément).
Quelqu’un comprend quelque chose à cet incroyable confusion de prix?
, le 26.07.2006 à 13:45
Je recherche un logiciel de reconnaissance. Apparement certains préfère omnipage.
J’ai readiris livré en bundle avec un stylo scanner, il fonctionne pas mal mais je n’ai pas réussi à automatiser complétement des processus de conversion en pdf depuis un chargeur de documents sur le scanner.
Est-ce que cette fonction demande la version pro?
Est-ce que je fais un truc faut?
Est-ce que ominpage fait cela très bien?
Bref je suis prenneur de toutes infos la dessus.
merci
, le 08.07.2007 à 18:31
J’ai acheté en dundle avec le scanner scansnap la version 11 de readiris. je n’ai toujours pas trouvé de fonctions d’automatisation pour scanner/ocr un grand nombre de documents. c’est un peu con pour un scanner avec chargeur… enfin si quelqu’un à trouvé le truc…